現代社会において、人工知能(AI)技術は目覚ましい発展を遂げ、私たちの生活や仕事のあり方を大きく変えつつあります。特に、生成AI分野では、人間が作成したかのような自然な文章や美しい画像を生成する能力が注目を集めています。近年、AI開発企業は、単なる生成能力にとどまらず、自社のモデルが持つ「推論」能力を盛んにアピールしています。数学オリンピックや競技プログラミングといった、複雑で論理的な思考を要する課題において、AIが人間のトップレベルに匹敵する、あるいはそれを超える成果を上げたという報告は、もはや珍しいものではなくなりました 1。こうした華々しい成果は、まるでAIが人間のように思考し、問題を解決しているかのような印象を与え、思考する機械、すなわち汎用人工知能(AGI)の実現が間近に迫っているかのような期待を抱かせます 3。
しかし、その一方で、AI研究の最前線では、こうした「推論能力」の本質について、より慎重な議論が長年にわたり続けられてきました。果たして、現在の生成AIは、人間が行うような意味での「思考」や「理解」を通じて問題を解いているのでしょうか。それとも、膨大な学習データから統計的なパターンを抽出し、それを巧みに組み合わせることで、あたかも推論しているかのように振る舞っているだけなのでしょうか 2。この問いは、AI技術の真の能力と限界を理解し、その未来を展望する上で極めて重要です。
この記事では、この問いに迫るため、近年発表された二つの重要な研究論文に焦点を当てて分析を行います。一つはApple社、もう一つはGoogle DeepMind社の研究者たちによるもので、どちらも生成AIの推論能力を深く掘り下げ、その実態に鋭いメスを入れています 2。これらの研究が特に興味深いのは、AI技術を牽引するまさにその企業内部から、現在の技術が抱える根本的な課題を指摘している点にあります。これは、華やかなマーケティングの裏側で、開発者自身が性能と真の理解との間に存在するギャップを認識し、それを克服しようと真摯に取り組んでいることの証と言えるでしょう。これらの論文は、AIの能力を否定するものではなく、むしろその限界を正確に診断し、より堅牢で汎用的な知能、すなわち真のAGIへと至るための道筋を照らし出す、貴重な土台となるものです 3。
本記事を通じて、読者の皆様には、生成AIが示す「推論」のからくり、その能力と、同時に露呈した根深い課題について、ご紹介いたします。
Table of Contents
「推論する生成AI」の仕組み
最近のAIの「推論」能力に関する議論を正確に理解するためには、まずその背景にある技術的な基盤について知っておく必要があります。ここでは、「大規模言語モデル(LLM)」、「思考の連鎖(Chain-of-Thought)プロンプティング」、そして「大規模推論モデル(LRM)」という三つの重要な概念を順に解説していきます。
大規模言語モデル(LLM)の基本
今日の生成AIの中核をなしているのが、大規模言語モデル(Large Language Models、略してLLM)です。LLMは、基本的には自己回帰モデルと呼ばれる仕組みで動作します 6。これは、文章や単語の並びが与えられたときに、次に来る可能性が最も高い単語(専門的にはトークンと呼ばれます)を予測するという作業を延々と繰り返すものです。例えば、「今日の天気は」という入力があれば、「晴れです」や「雨になりそうです」といった、統計的に最もあり得る続きを生成します。この単純な原理に基づきながらも、インターネット上のテキストなどをはじめとする、想像を絶するほど膨大な量のデータを学習させることで、LLMは人間が書いたかのように流暢で、文法的に正しい文章を生成する能力を獲得します 6。重要なのは、このプロセスが、文章の意味を人間のように理解しているわけではなく、あくまで単語と単語の間の統計的な関連性、つまりパターンを学習した結果であるという点です。
思考の連鎖(Chain-of-Thought)プロンプティング
LLMは、その基本的な仕組みから、直感的に答えられるような質問には強い一方で、複数のステップを踏んで考える必要がある複雑な問題には、間違いを犯しやすいという性質がありました。この課題を克服するために考案されたのが、「思考の連鎖(Chain-of-Thought、略してCoT)プロンプティング」という技術です 8。これは、AIに対して最終的な答えだけを求めるのではなく、「ステップバイステップで考えてください」や「あなたの思考プロセスを説明してください」といった指示を与えることで、問題解決に至るまでの中間的な思考過程を文章として書き出させる手法です 8。
あたかも人間が数学の問題を解くときに、途中の計算式を書き出すのに似ています。このCoTプロンプティングを用いることで、算術問題や論理パズルのような、多段階の推論を必要とするタスクの正答率が劇的に向上することが示されました 7。また、AIがどのような論理でその結論に至ったのかが可視化されるため、プロセスの透明性が高まり、間違いの原因を特定しやすくなるという利点もあります 12。
大規模推論モデル(LRM)の登場
CoTプロンプティングの有効性が明らかになると、AI開発企業は、この「段階的に思考する」能力をさらに強化したモデルの開発に乗り出しました。こうして登場したのが、「大規模推論モデル(Large Reasoning Models、略してLRM)」です 13。LRMは、基盤となるLLMに対して、CoTを含む論理的な思考プロセスが含まれたデータセットを追加で学習させたり、強化学習(Reinforcement Learning)と呼ばれる手法を用いて、より正確で一貫性のある思考の連鎖を生成できるように重点的に訓練されたモデルを指します 1。この強化学習では、モデルが生成した思考プロセスが最終的に正しい答えに結びついた場合に「報酬」を与え、間違っていた場合には「罰」を与えることで、望ましい推論パターンを強化していきます 14。
現在、各社が「推論するAI」や「思考するAI」として宣伝しているモデルの多くは、このLRMに該当します 6。しかし、ここで一つの重要な問いが浮かび上がります。CoTプロンプティングを強化したLRMは、本当に問題の論理構造を「理解」して思考しているのでしょうか。それとも、膨大な学習を通じて、「思考しているように見える文章のパターン」を生成するのが非常に上手になっただけなのでしょうか。この問いこそが、本記事の核心であり、続く章で分析する二つの論文が光を当てようとしている問題なのです。
この構造、つまり統計的な次単語予測という土台の上に、CoTという行動を模倣させる層を重ねるというアプローチは、AIの振る舞いを高度化させる巧妙な工学的解決策ですが、その根底にあるメカニズム自体を変えるものではない、ということなんですね。そして、この点にこそ、現在の「推論するAI」が抱える限界の根源が潜んでいます。
Apple社が示した「思考の錯覚」
生成AIが真に推論能力を持つのであれば、既知の問題の難易度を少しずつ上げていっても、それに追随して問題を解き続けられるはずです。Apple社の研究者たちは、この仮説を検証するために、非常に巧みな実験を行いました。彼らの研究は、LRMが示す「思考」が、ある種の錯覚である可能性を強く示唆しています。
実験の設計:スケーラブルな論理パズル
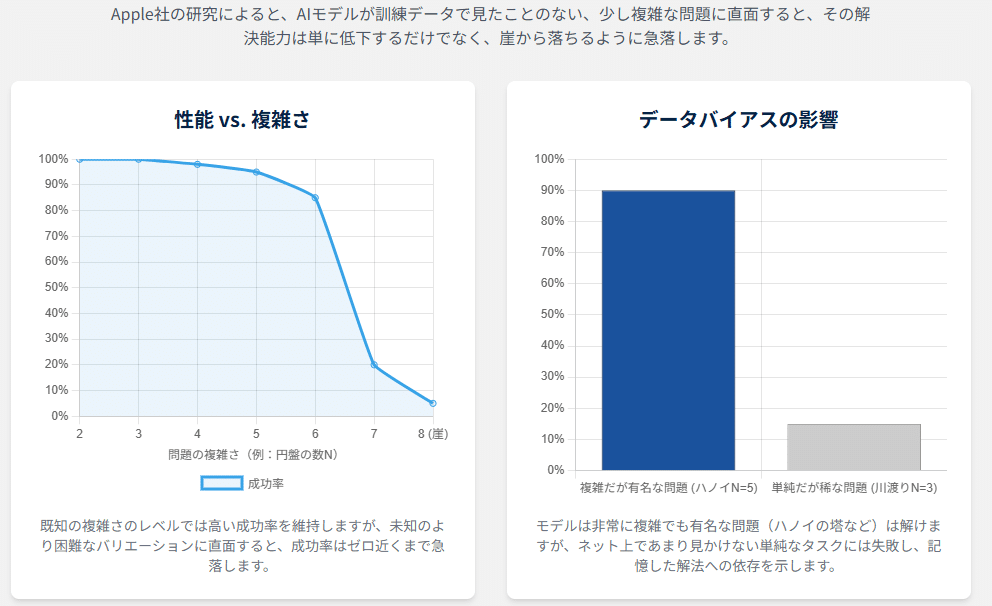
研究チームは、LRMの汎用的な問題解決能力を厳密に評価するため、四つの古典的な論理パズルを実験に採用しました 16。具体的には、「ハノイの塔」「チェッカージャンピング」「川渡りパズル」「ブロックワールド」です。これらのパズルが選ばれた理由は、その難易度を一つのパラメータ、例えばハノイの塔であれば円盤の数「N」を増減させるだけで、体系的かつ正確に調整できる点にありました 17。一般的な数学のベンチマークテストでは、その問題がAIの学習データに偶然含まれていたために解けてしまう「データ汚染」のリスクが常に付きまといますが、このように難易度を自在に変えられるパズルを用いることで、AIが未知の複雑さに対してどれだけ柔軟に対応できるか、その真の一般化能力を試すことができるわけです 16。
発見1:「推論の崖」現象
実験の結果は衝撃的なものでした。各パズルにおいて、複雑さのパラメータ「N」を徐々に増やしていくと、テストされたLRMの正答率は、ある特定の複雑さを超えた瞬間に、なだらかに低下するのではなく、突如としてほぼゼロにまで急落したのです 16。研究者たちはこの現象を「推論の崖(Reasoning Cliff)」と名付けました。これは、モデルの推論能力が、問題の難易度の上昇に対して頑健ではなく、ある限界点を超えると完全に破綻してしまうことを示しています 17。もしAIが問題解決のアルゴリズムを真に理解しているのであれば、複雑さが増すにつれて徐々に性能が落ちることはあっても、このように崖から落ちるような挙動は考えにくいでしょう。この結果は、モデルの能力が、学習データに含まれていた問題の複雑さの範囲内に固く閉ざされている可能性を示唆します。
発見2:逆説的な「推論努力」の減少
さらに不可解な現象が観測されました。研究チームは、モデルが思考プロセスとして生成したトークン(単語)の数を「推論努力」の指標として計測しました。当然、問題が複雑になればなるほど、より多くの思考ステップが必要になるため、この「推論努力」は増加すると期待されます。実際に、複雑さが中程度までは、モデルの推論努力は問題の難易度に応じて増加していきました。しかし、正答率が急落する「推論の崖」に近づくにつれて、その推論努力は、予期に反してなぜか減少し始めたのです 17。モデルにはまだ思考を続けるための十分な計算リソース(トークン生成上限)が残されているにもかかわらず、です。
これは、モデルが自らの能力を超えるほど複雑な問題に直面したとき、より深く考えようと努力するのではなく、むしろ思考を放棄してしまっているように見えます。この現象は、モデルが意識的に「諦めて」いるわけではありません。むしろ、学習したパターンから大きく外れた未知の領域に足を踏み入れたことで、次に出力すべきもっともらしいトークンの系列を見つけられなくなり、結果として短い、不完全な応答しか生成できなくなるという、モデルの統計的な性質の現れと解釈できます。
発見3:学習データの偏りという証拠
モデルの能力が、真の推論ではなく記憶に依存していることを示す、より決定的な証拠も見つかりました。あるLRMは、解くのに最低でも31手かかる複雑な「ハノイの塔」(円盤の数が5個の場合)の問題を解くことができたにもかかわらず、それよりもはるかに単純な、11手で解ける「川渡りパズル」(登場人物が3組の場合)には一貫して失敗したのです 18。研究者たちはこの奇妙な結果について、ハノイの塔は非常に有名で、インターネット上に解法や例が豊富に存在するため、モデルの学習データに大量に含まれていた可能性が高いと推測しています。一方で、川渡りパズルの特定のバリエーションは比較的データが少なく、モデルがその解法パターンを学習する機会がなかったのではないか、というわけです 19。これは、モデルが汎用的な計画立案能力を持っているのではなく、特定の「よく知られた問題」の解法パターンを記憶し、それを再生しているに過ぎないことを強く裏付けています。
Apple社の研究が明らかにした「推論の崖」と「推論努力の減少」、そして「学習データの偏り」という三つの現象は、現在のLRMが持つ「推論能力」が、学習データという名の見えない壁に囲まれた、限定的なものであることを浮き彫りにしました。モデルは、その壁の内側、つまり既知のパターンの範囲内では驚くべき性能を発揮しますが、一歩でも壁の外に出ると、その能力はもろくも崩れ去ってしまうのです。
Google DeepMind社が暴いた「過剰思考」
Apple社の研究が、問題が「複雑すぎる」場合にLRMの推論能力が破綻することを示したのに対し、Google DeepMind社の研究チームは、全く逆の角度からこの問題にアプローチしました。彼らは、問題が「単純すぎる」場合に何が起こるかを検証し、LRMの思考プロセスのさらなる奇妙な側面を明らかにしました。
新たな評価軸:「アンパズル」の導入
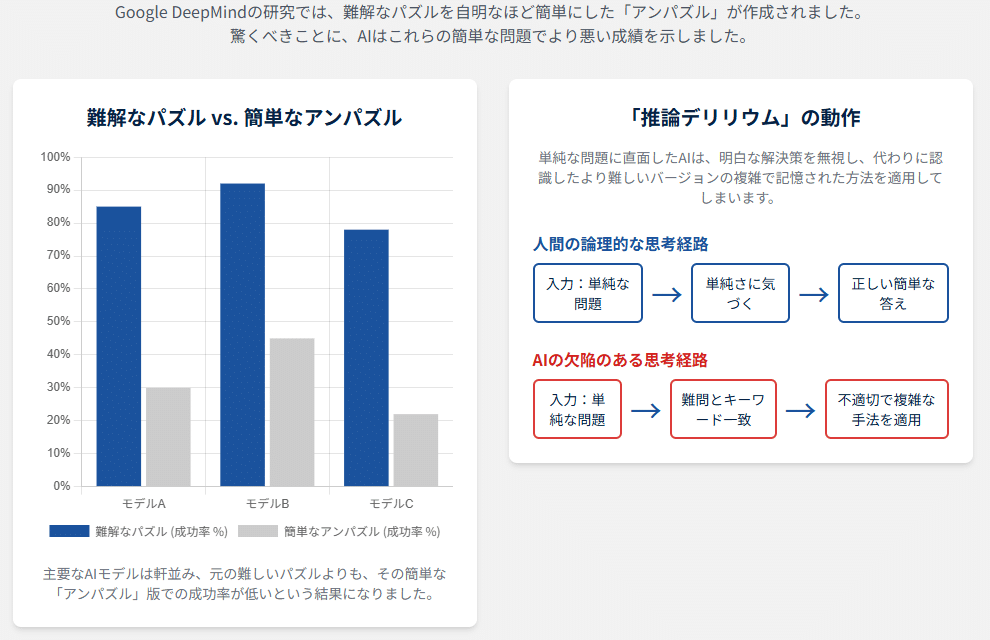
この研究の独創性は、「アンパズル(Unpuzzle)」という評価手法にあります 20。研究者たちは、まずインターネット上でよく知られている難解な論理パズルを多数収集しました。次に、それぞれのパズルに最小限のテキスト修正を加え、その答えが誰にとっても自明になるほど簡単な問題へと作り変えました。これが「アンパズル」です 20。
例えば、有名な「3色のカメレオン」というパズルがあります。これは、異なる色のカメレオンが出会うと別の色に変わるというルールのもと、最終的に全てが同じ色になれるかを問う、やや複雑な数学的不変量の考察を必要とする問題です。研究者たちは、このパズルのカメレオンの初期の数を少し変えるだけで、「紫と黄色のカメレオンの数が同数」という状況を作り出しました。こうなると、これらが全てペアになってマルーン色に変わるだけで問題は解決するため、答えは考えるまでもなく「イエス」となります。これがカメレオン問題のアンパズルです 21。さらに、モデルが表面的な単語だけに反応していないかを確かめるため、カメレオンをサッカークラブのファンに置き換えるなど、文脈だけを変えて論理構造は全く同じにした「文脈シフト・アンパズル」も用意されました 20。
衝撃的な結果:難問よりも簡単な問題が解けない
この独創的なパズル群を最新のLRMに解かせた実験の結果は、研究者たちの予想を上回る、驚くべきものでした。テストされた全てのLRMが、元の難しい「パズル」よりも、自明なはずの簡単な「アンパズル」の正答率の方が著しく低いという、直感に反する結果を示したのです 20。真の推論能力を持つ存在であれば、難しい問題が解けるなら、それより簡単な問題はより容易に解けるはずです。この結果は、LRMが問題の論理的な構造を理解して解いているのではない、という仮説を強力に支持するものです。
「推論デリリウム」という病理
なぜこのような奇妙な逆転現象が起きるのでしょうか。研究チームは、モデルの思考プロセスを詳細に分析し、その原因を「推論デリリウム(Reasoning Delirium)」と名付けました 20。これは、モデルが簡単なアンパズルを提示された際に、その単純な解法を無視し、代わりに学習データとして記憶している元の難しいパズルの複雑な解法手順を誤って適用してしまう現象を指します 21。
前述のカメレオンのアンパズルを例にとると、モデルは「紫と黄色をペアにすればよい」という単純な答えに気づかず、なぜか元の難問を解くために使われる「不変量」や「モジュロ演算」といった高度な数学的議論を長々と展開し始めるのです 21。これは、モデルが「カメレオン」「色が変わる」といったキーワードに反応し、それに紐づけられた最も確率の高い思考パターン、すなわち元の難問の解法を機械的に再生していることを示しています。モデルには、まず問題の本質的な難易度を評価し、それに適した解法を選択するという、人間なら当たり前に行うメタ認知的な能力が欠けているのです。これは「過剰な思考」というよりは、特定の入力合図に対して、知っている唯一の応答パターンを頑なに実行している状態と言えます。
正しい答え、間違った思考プロセス
さらに興味深いことに、モデルがアンパズルの最終的な答え自体は正しく「イエス」と回答した場合でさえ、その結論に至るまでの思考プロセスを見ると、やはり元の難しいパズルの誤った論理展開が記述されているケースが観察されました 2。これは、モデルが生成する「思考の連鎖」が、必ずしもその最終的な答えを導き出すための真の思考プロセスではなく、単にそれらしく見えるように生成された独立したテキストである可能性を示唆しています。
Google DeepMind社の研究は、LRMの知識が、柔軟で抽象的な原理の理解ではなく、特定の文脈に固く結びついた、極めて「脆い」ものであることを明らかにしました。この「推論デリリウム」という現象は、現実世界のタスクにAIを応用する上での重大なリスクを示唆しています。現実の問題は、教科書の例題のように常にクリーンであるとは限りません。表面上はよく知られたケースに似ていても、一つだけ決定的に重要な細部が異なる、といった状況は頻繁に起こり得ます。そのような状況で、AIがその僅かな違いを見過ごし、記憶した標準的な手順を盲目的に適用してしまえば、壊滅的な結果を招きかねないのです。
根本原因は何か―過学習
Apple社とGoogle DeepMind社の二つの研究が明らかにした、一見すると異なるLRMの奇妙な振る舞い、すなわち「複雑すぎる問題での破綻」と「単純すぎる問題での混乱」。これらは、実は同じ根源的な問題から生じています。その問題とは、機械学習の分野で古くから知られている「過学習(Overfitting)」という現象です。

機械学習における「過学習」とは
過学習とは、AIモデルが訓練に使われたデータ(学習データ)に過剰に適応しすぎてしまう状態を指します 24。過学習に陥ったモデルは、学習データに含まれる問題に対しては非常に高い正答率を示しますが、そこから少しでも外れた未知のデータや新しいパターンの問題に直面すると、途端に性能が低下してしまいます 24。これは、モデルが問題解決の根底にある普遍的な法則や一般化された知識を学ぶのではなく、学習データに含まれる個々の問題と答えのペアを、いわば「丸暗記」してしまっている状態です 26。試験勉強に例えるなら、教科書の練習問題の解法を完璧に暗記したものの、その背後にある公式や概念を理解していないため、少し数字や設定を変えられた応用問題が出ると全く手が出せなくなる状態に似ています。
二つの論文が示す過学習の兆候
この過学習というレンズを通して二つの論文の結果を改めて見てみると、両者が示す現象は、過学習の典型的な症状として見事に説明できます。
まず、Apple社の研究で観測された「推論の崖」は、モデルが学習データには含まれていなかったであろう、より複雑な問題に対して一般化できなかったことを示しています 16。モデルは、ある一定の複雑さまでの問題パターンは「暗記」していましたが、その範囲を超えた未知の領域(専門的には分布外データと呼ばれます)に対応する能力を持っていなかったのです 24。
次に、Google DeepMind社の研究で発見された「推論デリリウム」は、過学習の別の側面を露呈させています 20。モデルは、問題の表面的な特徴(キーワード)と、それに対応する特定の解法パターンをあまりにも強く結びつけて記憶してしまったため、問題の論理構造が単純化されても、その表面的な特徴に引きずられて不適切な解法を頑なに適用してしまいました 28。これは、問題の深い構造ではなく、表面的な統計的相関を学習してしまった結果に他なりません 4。
このように、両研究の結果は、現在のLRMが、人間のように問題の本質を抽象化して理解しているのではなく、膨大な学習データから抽出した表面的なパターンに過剰に適合している、すなわち過学習の状態にあることを強く示唆しているのです。
ハルシネーションとの関係
この問題は、生成AIがもっともらしい嘘をつく「ハルシネーション(幻覚)」として知られる現象とも深く関連しています。ハルシネーションの原因の一つにも、過学習が挙げられています 29。特定の専門分野のデータに過剰に特化して学習したモデルは、その専門外の質問をされると、自信満々に、しかし全くの誤りである情報を生成してしまうことがあります。今回観測された推論の失敗は、このハルシネーションが、論理的な問題解決という、より構造化されたタスクにおいて現れた特殊な形態と捉えることができます。
現在のAI開発における主流のアプローチは、モデルの規模と学習データの量をひたすら増大させるというものです。しかし、この「スケール至上主義」とも言えるアプローチは、皮肉にも、この過学習の問題を助長している可能性があります。学習データがインターネット全体を覆うほど巨大になれば、モデルは世の中のほとんどの既知の問題やベンチマークテストの答えを「記憶」することが可能になります。これにより、モデルはあたかも汎用的な知能を獲得したかのように見えますが、その実態は巨大な記憶力に支えられたものに過ぎないかもしれません。Apple社やGoogle社の研究が巧みだったのは、インターネット上には存在しないであろう新しい問題(例えば、極端に複雑なハノイの塔や、自明なカメレオンパズル)を作り出すことで、この「知性の錯覚」の皮を剥がしてみせた点です。これは、現在のスケーリング一辺倒のアプローチが、既知の問題に対する性能を最適化する一方で、未知の問題に対処する真の能力の育成を妨げている可能性を示唆しており、AI研究の将来にとって重大な問いを投げかけています。
人間の知性との比較:一般化と抽象化の能力
生成AIが示す推論の限界をより深く理解するためには、それを人間の知性の特徴と比較することが有効です。特に、「一般化」と「抽象化」の能力において、現在のAIと人間との間には根本的な違いが存在します。
パターン照合と真の理解
これまでの分析で見てきたように、現在のAI、特にLRMの動作原理は、本質的には高度なパターン照合に基づいています。膨大なデータの中から統計的な相関関係を見つけ出し、与えられた入力に対して最もそれらしい応答を生成します 4。一方、人間の知性は、単なるパターンの記憶にとどまりません。私たちは、物事の背後にある因果関係を理解し、世界の仕組みに関する内的な「メンタルモデル」を構築します 4。雨が降ると傘をさすのは、「雨」と「傘」という単語が一緒に出現することが多いからではなく、「雨に濡れると不快である」「傘は水を弾く」という物理的、感覚的な因果関係を理解しているからです。この「なぜ」を理解する能力こそが、人間が未知の状況にも柔軟に対応できる力の源泉となっています。
抽象化の力:「偽コイン」問題に見る思考
この違いを端的に示すのが、Google DeepMind社の研究で用いられたパズルの一つ、「天秤と偽コイン」の問題をさらに単純化した例です。もし、「天秤を使って、複数枚のコインの中から重さの違う一枚の偽コインを見つけ出す」という問題の代わりに、「ここに並んでいるコインは、全てが偽コインです。どれが偽コインか当ててください」と問われたら、人間は即座にこの問いが無意味であることに気づきます。なぜなら、私たちはこのパズルの本質が「他と異なるものを見つける」という抽象的な概念であることを理解しており、「全てが同じ(偽コイン)」なのであれば、比較対象が存在せず、課題自体が成立しないと判断できるからです。
しかし、これまでの研究結果から推測するに、LRMはこのように単純化された問題に直面すると、混乱を示す可能性が高いでしょう 20。モデルは「天秤」「コイン」「偽コイン」といったキーワードに反応し、学習データから記憶している複雑な秤量戦略を適用しようと試みるかもしれません。これは、モデルが問題の「本質」を抽象化する能力を欠いており、表面的な言葉のパターンに固執していることを示しています。人間の思考の根幹をなすこの抽象化能力こそ、現在のAIが未だ獲得できていない重要な要素なのです 31。
常識と文脈的学習
さらに、人間の知性は「常識」という広範な背景知識と、身体的な経験を通じた文脈的な学習に支えられています 33。私たちは、少ない経験からでも効率的に学ぶことができますが、それは新しい情報を、これまでに培ってきた世界の仕組みに関する膨大な知識体系の中に位置づけることができるからです 30。AIは、このような身体性や実世界との相互作用から得られる暗黙的な知識を持たないため、統計的なパターンを学習するために膨大な量の明示的なデータを必要とします。そして、その結果として、しばしば基本的な常識を欠いた、奇妙な間違いを犯すのです 33。
結局のところ、LRMに見られる推論の限界は、単なる技術的な欠陥というよりも、認知のより深い層、すなわち、世界に関する堅牢で、因果的で、抽象的なモデルが欠如していることの現れと言えます。現在のAIは、言語処理という非常に高度な「上部構造」を、極めて脆弱な「土台」の上に築いているようなものです。この観点から見れば、Apple社やGoogle社の研究で示された失敗は、驚くべきことではなく、むしろ現在のAIアーキテクチャの性質から予測される、必然的な結果だったのかもしれません。そしてこれは、人間のような真の推論能力を実現するためには、単なる統計的パターン照合を超える、新たなアーキテクチャへのパラダイムシフトが必要であることを示唆しています。
次世代AIへの道標
本記事では、Apple社とGoogle DeepMind社による二つの重要な研究を通じて、現在の「推論する生成AI」が抱える能力の限界と、その根本原因について深く掘り下げてきました。その分析から見えてきたのは、現在のAIが示す「推論」は、人間のような真の思考や理解とは異なり、学習データに基づく精巧なパターンマッチングの域を出ていないという現実です。この認識は、次世代のAI研究が目指すべき方向性を考える上で、重要な出発点となります。

新たなベンチマークの必要性
まず、両論文が一致して指摘しているのは、AIの真の能力を測るための新たな評価基準、すなわち新しいベンチマークの必要性です 2。既存の多くのベンチマークは、既知の問題に対する正答率を測ることに重点を置いており、結果としてAIに「問題を丸暗記」することを促してしまっている側面があります。これに対し、Google DeepMind社の「アンパズル」のようなアプローチは、モデルが表面的なパターンに頼らず、論理構造そのものを理解しているかを試すものであり、非常に示唆に富んでいます 20。今後は、このような一般化能力や堅牢性を評価するために特別に設計された、データ汚染のリスクが低いベンチマークの開発が不可欠となるでしょう。例えば、AIがこれまで見たことのない新しい記号やルールを用いて抽象的な思考ができるかを試すようなテストも、その重要な候補となります 31。
自己回帰モデルの限界とAGIへの道
次に、より根本的な問いとして、現在の主流である自己回帰モデルをひたすらスケールアップさせていくだけで、人間と同等かそれ以上の知能を持つ汎用人工知能(AGI)に到達できるのか、という問題が挙げられます 2。本記事で見てきたように、このアプローチは、質的な限界に直面している可能性があります 3。どれだけ学習データと計算量を増やしても、それが本質的にパターンマッチングである限り、未知の状況に対応する真の一般化能力や、物事の本質を捉える抽象化能力の獲得には繋がらないかもしれません。AGIへの道は、単なる次単語予測という枠組みを超えた、新たな発想を必要としているのです。
ニューロシンボリックAIという可能性
では、その新たな発想とは何でしょうか。ここで有望な研究分野として注目されるのが、「ニューロシンボリックAI」です 35。これは、近年のAIの主流であるニューラルネットワーク(パターン認識や非構造化データからの学習に長ける)と、古典的なAI研究の中心であったシンボリックAI(記号論理に基づいた構造的な推論や解釈可能性に長ける)を融合させようというハイブリッドなアプローチです 37。
具体的には、ニューラルネットワークのアーキテクチャの中に、論理的なルールや知識構造を明示的に組み込むことで、AIがデータから学習する能力と、論理的に思考する能力の両立を目指します 5。このアプローチは、本記事で明らかになったLRMの弱点、すなわち、脆さ、不透明さ、一般化能力の欠如といった問題に、正面から取り組む可能性を秘めています。思考を模倣するだけでなく、真に理解し、説明可能な形で思考するAI。ニューロシンボリックAIは、その実現に向けた重要な一歩となるかもしれません。
AI研究の歴史は、支配的なパラダイムが厳密な検証によってその限界を露呈し、新たなパラダイムへと移行していく過程の繰り返しでした。現在、私たちはまさにそのような転換点に立っているのかもしれません。「スケールこそが全て」という考え方が、今回紹介したような研究によってその綻びを見せ始めています。これらの研究は、単に「LRMには欠陥がある」と指摘しただけでなく、AI研究の潮流を、純粋なスケールの追求から、より堅牢な推論能力を実現するためのアーキテクチャ革新へと向かわせる、重要な触媒となる可能性を秘めているのです。その先に、どのような知性の形が待っているのか、今後の研究の進展から目が離せません。
引用文献
- Reasoning language model - Wikipedia,https://en.wikipedia.org/wiki/Reasoning_language_model
- 「推論する生成AI」は実際には思考しているわけではなく、丸暗記した結果を返しているに過ぎない,https://tjo.hatenablog.com/entry/2025/07/23/173000
- Where would reasoning AI leave human intelligence? - The World Economic Forum,https://www.weforum.org/stories/2025/01/in-a-world-of-reasoning-ai-where-does-that-leave-human-intelligence/
- AI vs. Human Intelligence: Key Differences - AI Cosmos,https://ai-cosmos.hashnode.dev/the-fundamental-difference-between-ai-and-human-intelligence-pattern-matching-vs-true-understanding
- AI Reasoning in Deep Learning Era: From Symbolic AI to Neural–Symbolic AI - MDPI,https://www.mdpi.com/2227-7390/13/11/1707
- Reasoning Language Models: A Blueprint - arXiv,https://arxiv.org/html/2501.11223v1
- Large Reasoning Models: How o1 Replications Turned into Real Competition - Synthesis AI,https://synthesis.ai/2025/02/25/large-reasoning-models-how-o1-replications-turned-into-real-competition/
- What is chain of thought (CoT) prompting? | IBM,https://www.ibm.com/think/topics/chain-of-thoughts
- Chain-of-Thought Prompting: Step-by-Step Reasoning with LLMs | DataCamp,https://www.datacamp.com/tutorial/chain-of-thought-prompting
- www.ibm.com,What is chain of thought (CoT) prompting? | IBM
- Chain of Thought Prompting Guide - PromptHub,https://www.prompthub.us/blog/chain-of-thought-prompting-guide
- Chain of Thought Prompting Guide - Medium,https://medium.com/@dan_43009/chain-of-thought-prompting-guide-3fdfd1972e03
- Large Reasoning Models (LRMs) - Emergent Mind,https://www.emergentmind.com/topics/large-reasoning-models-lrms
- What are Large Reasoning Models (LRMs)? | AI21,https://www.ai21.com/glossary/large-reasoning-models/
- [2503.11074] Exploring the Necessity of Reasoning in LLM-based Agent Scenarios - arXiv,https://arxiv.org/abs/2503.11074
- Can Large Langauge Models Really Reason? | by Dr. Vijay Srinivas Agneeswaran | Jun, 2025,https://a-vijaysrinivas.medium.com/can-large-langauge-models-really-reason-43322999b988
- Investigating the Illusion of Thinking | by Adnan Masood, PhD. | Jun ...,https://medium.com/@adnanmasood/investigating-the-illusion-of-thinking-87469a818cb8
- (PDF) A Comment On "The Illusion of Thinking": Reframing the ...,https://www.researchgate.net/publication/392980427_A_Comment_On_The_Illusion_of_Thinking_Reframing_the_Reasoning_Cliff_as_an_Agentic_Gap
- Do the researchers at Apple, actually understand computational complexity? - Reddit,https://www.reddit.com/r/singularity/comments/1l6xmxf/do_the_researchers_at_apple_actually_understand/
- Frontier LLMs Still Struggle with Simple Reasoning Tasks - arXiv,http://arxiv.org/pdf/2507.07313
- (PDF) Frontier LLMs Still Struggle with Simple Reasoning Tasks - ResearchGate,https://www.researchgate.net/publication/393586628_Frontier_LLMs_Still_Struggle_with_Simple_Reasoning_Tasks
- Frontier LLMs Still Struggle with Simple Reasoning Tasks - arXiv,https://arxiv.org/html/2507.07313v1
- Frontier LLMs Still Struggle with Simple Reasoning Tasks - arXiv,https://arxiv.org/pdf/2507.07313
- What is overfitting in LLM fine-tuning? - Talbot West,https://talbotwest.com/ai-insights/what-is-overfitting-in-llm
- Exploring Robust Overfitting for Pre-trained Language Models | Request PDF,https://www.researchgate.net/publication/372917150_Exploring_Robust_Overfitting_for_Pre-trained_Language_Models
- Machine Learning Street Talk (MLST) - Spotify for Creators,https://anchor.fm/s/1e4a0eac/podcast/rss
- In artificial intelligence, what is the practical difference between memorizing, learning and reasoning? - Quora,https://www.quora.com/In-artificial-intelligence-what-is-the-practical-difference-between-memorizing-learning-and-reasoning
- ai_github | PDF | Computational Neuroscience | Algorithms - Scribd,https://www.scribd.com/document/842849229/ai-github
- The TWIML AI Podcast (formerly This Week in Machine Learning & Artificial Intelligence),https://www.globalplayer.com/podcasts/42KobX/
- Do Humans and AI Learn Similarly? You Might be Surprised: A Deep Dive into Human and AI Learning Mechanisms from a Medical Doctor's Perspective | by Ross W. Green, MD (Custom AI Studio) | Medium,https://medium.com/@custom_aistudio/do-humans-and-ai-learn-similarly-c91ce3571b35
- Benchmarking Abstract and Reasoning Abilities Through A Theoretical Perspective,https://icml.cc/virtual/2025/poster/44727
- Benchmarking Abstract and Reasoning Abilities Through A Theoretical Perspective - arXiv,https://arxiv.org/html/2505.23833v1
- Common Sense Is All You Need - arXiv,https://arxiv.org/html/2501.06642v1
- The Architecture of Thought: Reasoning in Human Cognition and Artificial Intelligence,https://www.alphanome.ai/post/the-architecture-of-thought-reasoning-in-human-cognition-and-artificial-intelligence
- Neuro-Symbolic AI: Combining Neural Networks with Symbolic Reasoning - ResearchGate,https://www.researchgate.net/publication/390173167_Neuro-Symbolic_AI_Combining_Neural_Networks_with_Symbolic_Reasoning
- Towards Data-And Knowledge-Driven AI: A Survey on Neuro-Symbolic Computing,https://www.computer.org/csdl/journal/tp/2025/02/10721277/2179549p9QY
- Modelling Symbolic Knowledge using Neural Representations - -ORCA - Cardiff University,https://orca.cardiff.ac.uk/id/eprint/144487/1/Modelling_Rules_and_Knowledge_Graphs_with_Embeddings.pdf
- Symbolic AI in Natural Language Processing: A Comprehensive Guide - SmythOS,https://smythos.com/developers/ai-models/symbolic-ai-in-natural-language-processing/
- Standard Neural Computation Alone Is Insufficient for Logical Intelligence - Powerdrill AI,https://powerdrill.ai/discover/summary-standard-neural-computation-alone-is-insufficient-cm6se9bzx9cvx07s315zh1tq9
